◾ 探索过程
在 MiniMax CN 官网看到还支持图片理解 MCP,于是想让 OpenClaw 自己连接这个 MCP 来实现图片识别。结果得到的答复是:需要额外安装 UVX,不建议连接 MCP,内置的 image 接口可以直接识别图片。
抱着试试看的心态,我直接发送了一张图片——结果真的识别出来了!
在此之前,使用 MiniMax Token Plan 之前尝试发送图片,得到的回复要么是无法识别,要么是乱回复。
◾ 深入探究
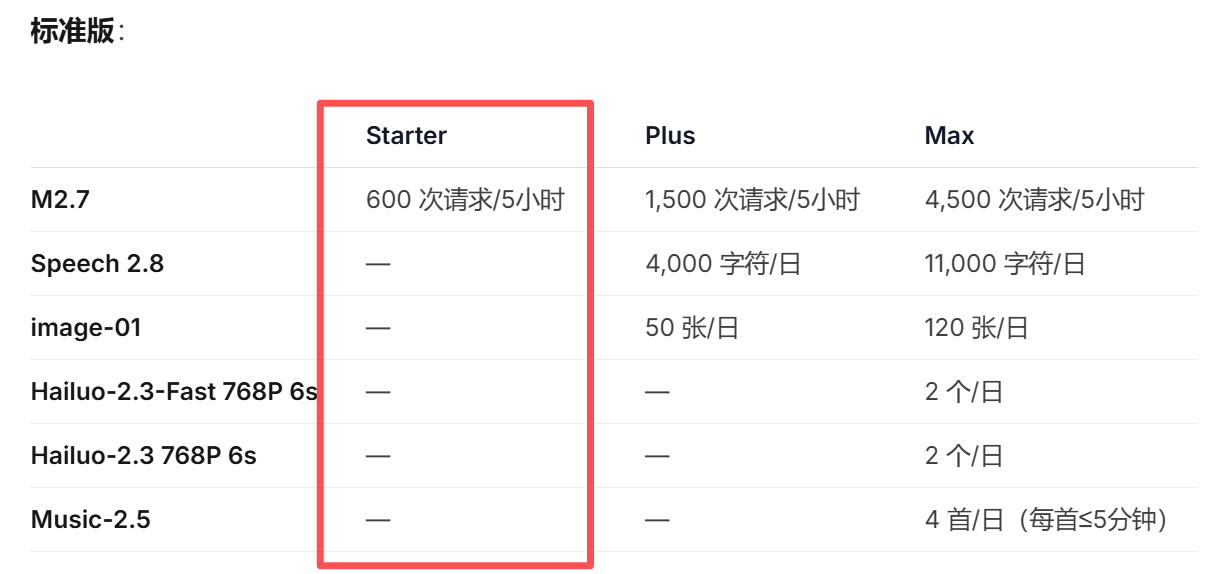
默认模型配置使用的是 MiniMax-M2.7(接口 MiniMax OAuth)。标准版 Starter 套餐官方介绍仅支持 MiniMax-M 系列纯文本模型,我也没有配置任何视觉模型——可为什么突然就能识别图片了?
经过几次追问 OpenClaw,终于搞清楚了:
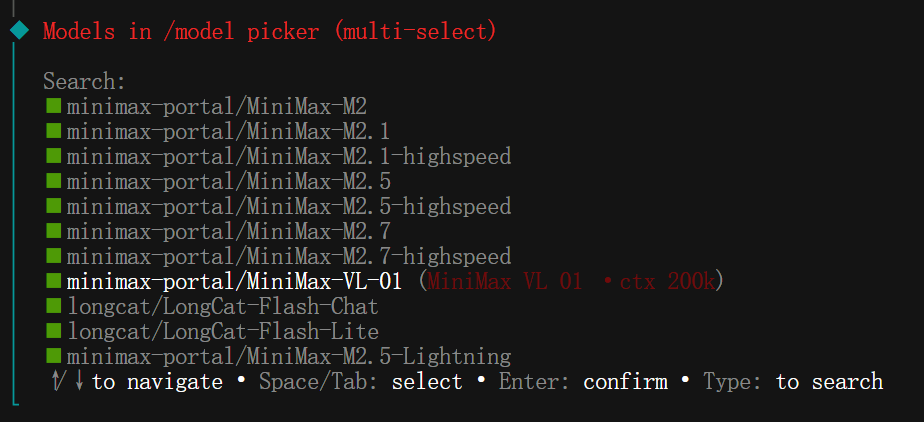
OpenClaw 在收到图片时,会自动在其模型提供商(接口 MiniMax OAuth)的模型列表中,选用名为 MiniMax-VL-01 的视觉模型来完成图片识别。
也就是说,MiniMax-VL-01 这个视觉模型是 OpenClaw 自动调用的,用户无需手动配置。
◾ 意外发现
第一次配置 MiniMax 时,我参照的是 MiniMax CN 官方文档,文档里并没有提到可以使用 MiniMax-VL-01 这个模型。
官方 Token Plan 套餐里没提,那去 OpenClaw 配置中看看 MiniMax OAuth 接口,果然有 MiniMax-VL-01 选项。这不知是何意,那我就全部打勾,看以后还有没有惊喜。😄
◾ 结论
・ MiniMax Token Plan(标准版 Starter)虽然官方文档没写,但实际支持图片理解
・ OpenClaw 会自动调用 MiniMax-VL-01 视觉模型处理图片
・ 无需额外安装 MCP 或配置,即可在对话中发送图片并获得识别结果
如果你也在用 OpenClaw + MiniMax,可以直接试试发图片,无异于将 MiniMax 的性价比提升一个档次。
🚀 MiniMax Token Plan 惊喜上线!新增语音、音乐、视频和图片生成权益。邀请好友享双重好礼,助力开发体验!
好友立享 9折 专属优惠 + Builder 权益,你赢返利 + 社区特权!
推荐使用MiniMax Token Plan玩龙虾:https://platform.minimaxi.com/subscribe/token-plan?code=3VQBWxlY4n&source=link


文章评论